
Stop enforcing Code Coverage as a Quality metric

“When a measure becomes a target, it ceases to be a good measure” - Goodhart's Law
Code coverage serves as a valuable metric for gauging the extent of code covered by test cases. However, using it as the management metric to determine code quality is misplaced.

I have observed teams implementing strict policies that emphasise achieving high code coverage, monitored through static analysis tools such as SonarQube. While this may seem like a disciplined approach to ensure quality, paradoxically, setting code coverage as a target can jeopardise overall code quality and maintainability.
To gain a deeper understanding, let's explore the intricacies of code coverage through examples and navigate through its potential pitfalls.
How code coverage works?
Depending on language and test framework, different test analysis tools measure code coverage can be measured at different levels. The common coverage criteria include:
Line Coverage: Measures the percentage of lines of code executed by the test suite
Branch Coverage: Measures the percentage of decision points (branches) that have been executed by test suite
Statement Coverage: Measures the percentage of executable statements that have been executed. (i.e. given a line may have multiple statements)
Class Coverage: Measure the percentage of classes covered by test suite
Function Coverage: Measures the percentage of functions that have been invoked by the test suite.
Let’s go through an example based on the popular Supermarket Kata.
I have some code in place and my code coverage is 100% on all accounts.

Does that mean my code quality is great and I don’t have any bugs or maintainability issues with my code? Not really.
Where are the gaps?
Code coverage as explained above, accounts for what a test suite executes, but not what it tests.
Here are some patterns that trick your code coverage in believing that your code quality is well covered for regression, while it’s not.
1. Tests without assertions
Imagine an Order class that lets you add items to order. You can pass in the item name(or identifier) to the add method, which validates if same item already exists in the Order list. If it exists, it increments the quantity, or else, it adds a new entry into the list.
Order.java
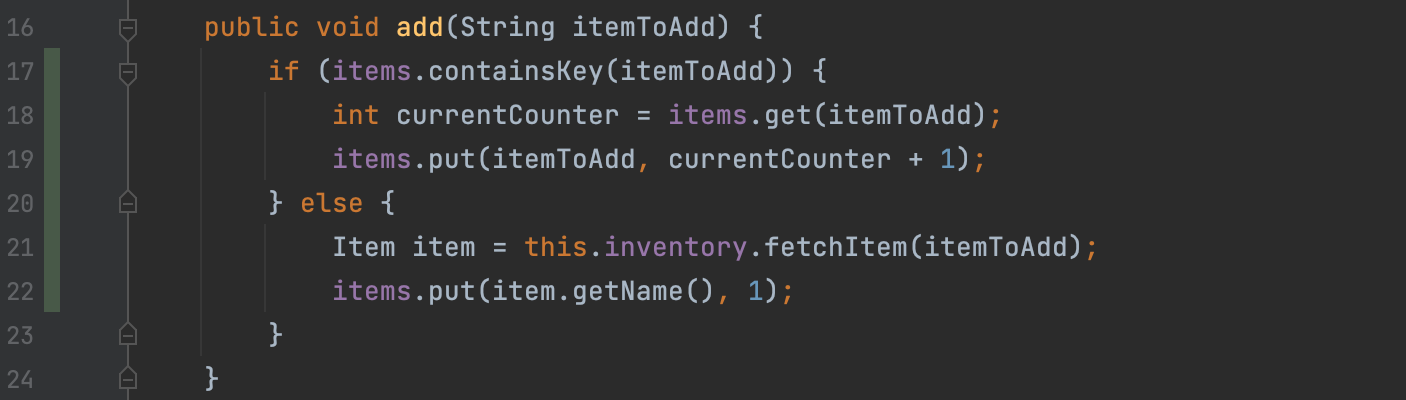
Above example has multiple lines and branches to test.
Below is the test in OrderTest class that intends to validate the Order add method by adding multiple items to the Order
OrderTest.java

In the coverage report, you will see 100% coverage

However, there is a big issue. The test doesn’t assert anything.
If I make modifications such as flipping conditions, altering logic (e.g., negating an if condition), or changing how quantity is added, there's a risk that my code may fail in production.
Though, my tests will continue to pass, giving a false assurance on quality
2. Mocks without verify
A more common variant of the above problem that I see often is about how teams use mocks.
Let’s examine the constructor of Order class.
Order.java

The Order depends on ItemInventory to fetch prices for items. Since ItemInventory connects to database to fetch the Item details and pricing strategy, to write an isolated test, it requires the ItemInventory object to be stubbed.
Let’s assume that adding an Item to Order requires multiple steps
Fetching
ItemfromItemInventorywhen available (Exception otherwise)Decrement
Itemquantity fromItemInventory
OrderTest.java

The test above asserts that an Item has been added to an Order. However, it doesn’t validate how Order interacts with ItemInventory. In fact, it doesn’t execute any behaviour within ItemInventory.
Is
Itemstock adjusted inItemInventory?How many times does Order invoke
ItemInventoryfetchItem method?How many times does Order invoke
ItemInventoryfetchPrice method?
Every mocked implementation must be associated with a verify statement to observe the interaction between calling object and its dependency.
The code above actually has a bug, but it won’t be caught given how the test is structured. Though the code coverage will continue to be 100%.
The test would start to fail as soon as you add verify statement revealing the bug.

3. Trivial tests
In his book, Unit testing - Principles, Practices and Patterns, Vladimir Khorikov, discusses how Unit tests should target the behaviour and not the structure of the system. Targeting structure of the system makes the tests brittle and hard to maintain.
He goes on to discuss, the concept of Trivial tests, which validate insignificant operations such as instantiating an object, or validating getters and setters. Such operations, on their own don’t exhibit any behaviour (Unless, there is a business logic or decision making involved).

While such tests may make the code coverage look healthy, they don’t add much value to overall code quality, until tested with a unit of behaviour.
Alternative to code coverage
Code coverage is the wrong goal to begin with as a measure of software quality. The pursuit of high coverage may encourage writing tests for quantity, while quality and maintainability continues to be an issue. Instead, the focus should be on proactive practices like Test-Driven Development (TDD), robust unit testing, and continuous integration. By prioritizing these practices, teams build quality into the software, ensuring reliability and maintainability. Code coverage, while useful, should be seen as a byproduct of these efforts rather than the ultimate goal.
This is a straw man. Of course if you write bad unit tests, coverage of your code by those unit tests isn't going to be useful.